 When it came to setup my remote backup machine, only three things were important: use of 4K disks, two disk redundancy (raidz2), and a reasonably efficient storage of variously sized files. Reading around internet lead me to believe
When it came to setup my remote backup machine, only three things were important: use of 4K disks, two disk redundancy (raidz2), and a reasonably efficient storage of variously sized files. Reading around internet lead me to believe volblocksize tweaking was what I needed.
However, unless you create zvol, that knob is actually not available. The only available property impacting file storage capacity is recordsize. Therefore I decided to try out a couple record sizes and see how storage capacity compares.
For the purpose of test I decided to create virtual machine with six extra 20 GB disks. Yes, using virtual machine was not ideal but I was interested in relative results and not the absolute numbers so this would do. And mind you, I wasn't interested in speed but just in data usage so again virtual machine seemed like a perfect environment.
Instead of properly testing with real files, I created 100000 files that were about 0.5K, 33000 files about 5K, 11000 files about 50K, 3700 files about 500K, 1200 files about 5M, and finally about 400 files around 50M. Essentially, there were six file sizes with each set being one decade bigger but happening only a third as often. The exact size for each file was actually randomly chosen to ensure some variety.
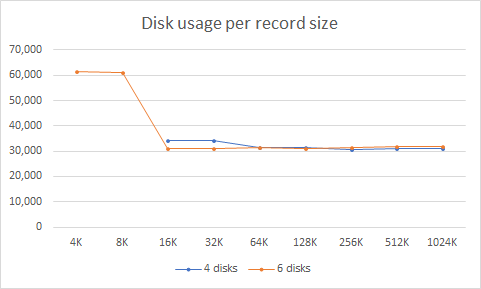
After repeating test three times with each size and for both 4 and 6 disk setup, I get the following result:
| 4 disks | 6 disks | |||
| Record size | Used | Available | Used | Available |
| 4K | - | 0 | 61,557 | 17,064 |
| 8K | - | 0 | 61,171 | 17,450 |
| 16K | 34,008 | 4,191 | 31,223 | 47,398 |
| 32K | 34,025 | 4,173 | 31,213 | 47,408 |
| 64K | 31,300 | 6,899 | 31,268 | 47,353 |
| 128K | 31,276 | 6,923 | 31,180 | 47,441 |
| 256K | 30,719 | 7,481 | 31,432 | 47,189 |
| 512K | 31,069 | 7,130 | 31,814 | 46,807 |
| 1024K | 30,920 | 7,279 | 31,714 | 46,907 |
Two things of interest to note here. The first one is that small record size doesn't really help at all. Quantity of metadata needed goes well over available disk space in the 4-disk case and causes extremely inefficient storage for 6 disks. Although test data set has 30.2 GB, with overhead occupancy goes into the 60+ GB territory. Quite inefficient.
The default 128K value is actually quite well selected. While my (artificial) data set has shown a bit better result with the larger record sizes, essentially everything at 64K and over doesn't fare too badly.
PS: Excel with raw data and script example is available for download.
PPS: Yes, the script generates the same random numbers every time - this was done intentionally so that the same amount of logical space is used with every test. Do note that doesn't translate to the same physical space usage as (mostly due to transaction group timing) a slightly different amount of metadata will be written.
One thought to “ZFS Record Size For Backup Machine”